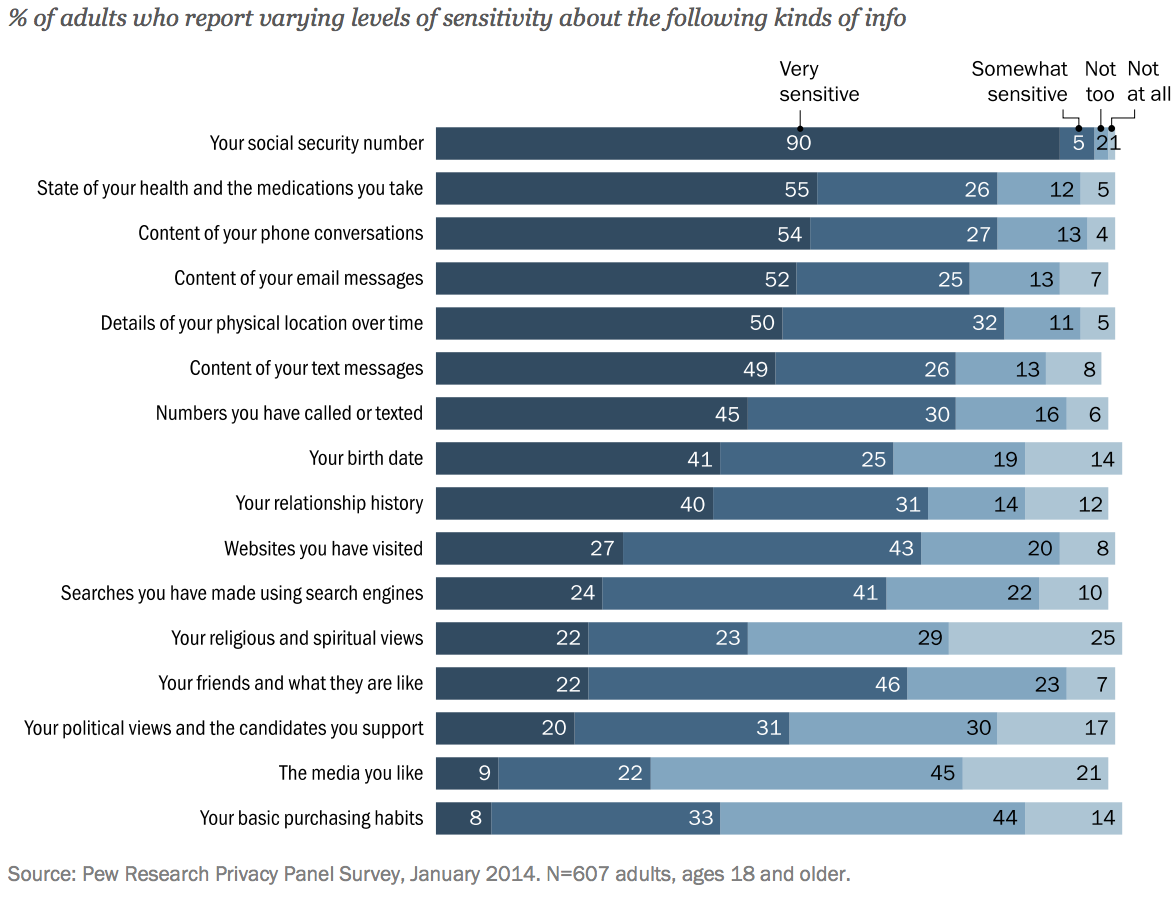
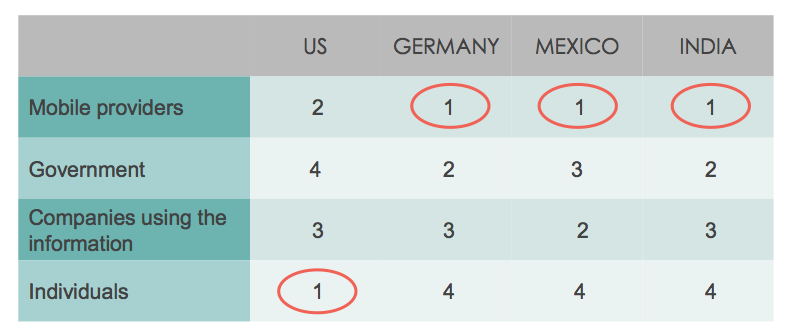
The personal data economy starts off with acquiring data on individuals from census information, public records, web trackers, surveys, and various other methods, some more and some less nefarious. Data is aggregated in data warehouses and sold by data brokers in large batches to whoever is interested in buying it (read more here). Most commonly it is either used for marketing and ad-targeting, or general market research. This happens constantly and mostly without our explicit consent, although often without our explicit descent either.

Many articles can be found on the net written by people who went to data warehouse and brokerage companies and requested to to see what they knew about them (one, two, three, etc.). More often than not the brokerages complied, and the results were a mix of surprise at some things that these companies got right like address histories, and perplexity at vague inferences which seemed to be off the mark like race and lifestyle type. All in all it seems a great deal of accurate data about us is out there, but it’s mixed in with a lot of noisy junk that makes little sense.
However, aside from being willing to tell you what they know (or think they know) about you, data brokerages will also let you ‘opt-out’ of their databases. Ken Gagne at Computerworld drew up a list of the 10 biggest data warehousing and brokerage companies, and went through the paces to see if he could opt-out of their data pools. Of the 10 he tried, he was able to effectively opt out of 9 of them with some caveats. The process was not always straightforward, but he’s documented it well so you can follow in his footsteps if you’d like. He notes at the end of the article that this is not a ‘fire-and-forget’ process. Just because you’re out doesn’t mean you won’t sneak back in when they purchase their next big batch of data. There is a service called PrivacyMate that offers to do the repeat work for you, but at $120 a year it doesn’t come cheap.